Messages on Rails Part 1 - Introduction to Kafka and RabbitMQ
Microservices, Service-Oriented Architecture (SOA) and in general, distributed ecosystems, have been on hype in the last several years. And that’s for a good reason! At certain point, The Majestic Monolith “pattern” might start causing issues, both from the purely technical reasons like scalability, tight coupling of the code if you don’t follow Domain-Driven Design or some other practices improving modularity, maintenance overhead, and also from organizational perspective since working in smaller teams on smaller apps is more efficient than working with huge team on an even bigger monolith which suffers from tight coupling and low cohesion. However, this is only true if the overall architecture addresses the potential problems that are common in the micro/macro-services world. One of these problems I would like to focus on is communication between apps and how the data flows between them.
How Can The Applications Talk To Each Other
There are multiple ways the applications could talk to each other but let’s focus on the most popular ones: shared database, HTTP API and messages.
Shared Database
It is arguable if we can talk about apps communicating with each other in this scenario; nevertheless, it’s one of the ways to solve the problem of getting data from one application to another. And apart from some particular scenarios, it’s the way that could give you a lot of headaches quite soon.
Initially, it might look like a great idea - you connect the other app to an existing database, and you don’t need to worry about the communication! If the other application is just responsible for reading from that database, maybe you won’t have any severe problems beyond increased load, issues of scaling and questionable access control (by default, the other app can do anything to that database). However, if you have multiple applications writing to the same database, you will undoubtedly have more serious issues - deadlocks, problems with data consistency as different constraints might apply to different applications, schema getting out of control with each application adding some custom tables and fields, which can turn out to be quite nasty - imagine one application acquiring Access Exclusive Lock on the entire table which turns out to be large (so the lock will not be released any time soon) thanks to some migration, while the other app was supposed to do some business-critical operations on that table that were also time-sensitive. Some of these problems are RDBMS-specific like locking during migration, but there is a very good chance anyway that you will be using either MySQL or PostgreSQL.
There are just too many things that can go wrong with having shared database that I would highly discourage from even trying that approach, maybe besides one single scenario - when what you need is exactly a replication of some data, e.g., to generate reports. In that case, you can set up PostgreSQL logical replication and let it replicate the data from the primary data source to a read-only replica containing only the data the application needs. Since PostgreSQL has a very reliable replication mechanism, you don’t need to reinvent the wheel, and you can take advantage of that feature. Keep in mind that logical replication was introduced in PostgreSQL 10, so it’s not available in the previous versions.
HTTP API
HTTP APIs, especially the RESTful APIs (although GraphQL has been getting quite popular in the last years), are arguably the most common blocks in microservices architecture as far as the communication between applications goes. REST architecture goes very well with HTTP, the communication between client and server is synchronous which makes it easy to reason about and debug, HTTP APIs are ubiquitous, and the developers are familiar with working with them. Also, HATEOAS and capabilities of getting precisely what you need from GraphQL make using with HTTP APIs easy, especially when working with Third-Party applications. Also, there is a lot of flexibility in implementing access control and authentication. On top of that, there are specifications that clearly define how JSON APIs should be built, which minimizes reinventing the wheel and makes it even easier to build a client for that kind of API.
Based on those advantages it might look like communication between services via JSON APIs is the best possible solution to the problem, right?
Well, not necessarily. If you have one or two applications communicating with some other application, maybe it’s not a bad idea, especially if the traffic is not huge and you don’t need to transfer gigabytes of JSON daily via HTTP.
However, what if you expect a massive load from the services and indeed you will be transferring gigabytes of JSON via HTTP? Do you really need flexible authorization for communication between internal services? And why deal with an extra overhead of non-persistent connections and SSL handshakes in the first place?
Those things are great for integration with Third-Party applications, but they bring very little value in a closed ecosystem. Nevertheless, that overhead is not the biggest problem here, let’s discuss something way more problematic: scaling.
Imagine that the API of one application is exposed to multiple other applications in your ecosystem. Also, the same application is used by “real” users who interact with it via UI. The immediate problem we have with that approach is that the traffic generated by the other services will be affecting regular users, which makes scaling decisions more tricky. To make it more complicated, let’s say that in our example ecosystem we have a lot of data, and each application will be reading gigabytes of data every day and each service fetches data periodically from the API, e.g., every 5 minutes. To limit the number of requests so that we don’t fetch the data that has been already fetched by the applications, we may want to implement some sort of data offset, which most likely will be based on the timestamp of the last fetch. We could send this timestamp that will filter out the records that haven’t changed after that time and drastically reduce the number of requests that way. However, in a big enough scale, that will not be enough to solve all the issues. There can be thousands of records to be fetched every 5 minutes, which will most likely be paginated - that means a lot of requests. Multiply it by the number of applications and the traffic looks even more depressing, especially if every application will fetch exactly the same data.
Either the answer to the problem will be caching, which might be tricky to implement since the services will be using timestamp-based offset, or we can switch from pull-based strategy to push-based strategy.
A push-based strategy will be a publish-subscribe pattern via HTTP. The benefit of that is that we could serialize the state of the record after every change only once (or just serialize a changeset and go in the direction of CQRS/Event Sourcing) and send the payload to every service subscribed to a given event. The benefit of this approach is serializing a payload only once instead of doing it on every request, we can avoid useless requests which might happen if nothing has changed in the last 5 minutes and we could balance the load efficiently by moving the delivery logic to some background jobs. The disadvantage of publish-subscribe via HTTP, a.k.a. webhooks, would be implementing HTTP APIs in every service. Also, each application will experience massive traffic on a large enough scale.
It’s great if your ecosystem offers this kind of features for limiting the number of requests to Third-Party Applications, but is it the most efficient way of handling communication between internal applications and scaling the ecosystem?
This type of communication is arguably quite common in the microservices world, and the funny thing is that in some aspects it’s no different than reimplementing messaging systems, but done in a less effective way.
There is a more efficient way to deal with the communication between internal services: using asynchronous messaging.
Asynchronous Messaging
Async messaging is a communication approach where a middleware, called message broker, connects producers of messages with consumers of those messages. Usually, a producer sends messages and the message broker is responsible for delivering them to proper consumers.
Thanks to having a message broker in-between the services, not only do we benefit from extra decoupling between the applications, but also we have way more flexibility as far as scalability goes.
Let’s take a look at two very popular message brokers that take different approaches to messages: RabbitMQ and Apache Kafka
RabbitMQ
RabbitMQ is a general purpose message broker supporting multiple protocols from which AMQP will be the one most interesting one to us. It implements a smart broker/dumb consumer model, which means the broker is responsible for delivering messages to the right place.
The essential design decision in RabbitMQ is that the producers shouldn’t directly push messages to the queues, from which the consumers can read messages and process them. Instead, producers send messages to exchanges, and the queues are connected to these exchanges. That way, the producer doesn’t know where exactly the message will be delivered and how many consumers are going to do anything with it if any! This kind of decoupling not only allows implementation of the publish-subscribe pattern, where multiple consumers using different queues bind to the same exchange and process the same message, but it also opens the way to quite a flexible routing (which we will cover in more details in the next part of this series). Once the consumer acknowledges the message, it is removed from the queue. Multiple producers can also subscribe to the same queue which will make them compete for the messages. The communication in a simple scenario as described above is illustrated in the following diagram:
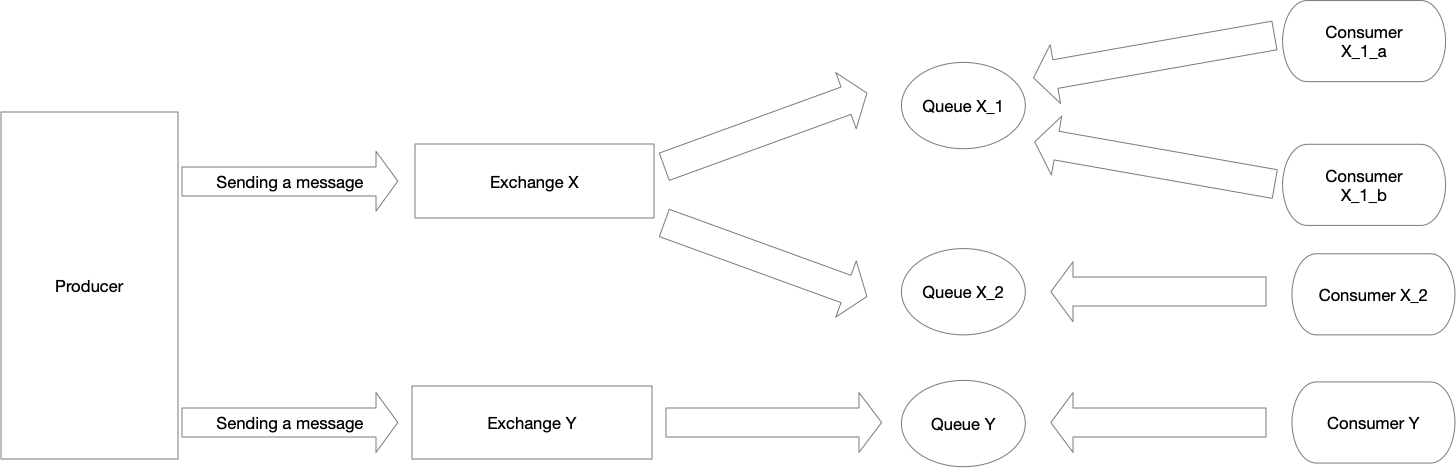
RabbitMQ is an excellent choice if you have complex routing scenarios, priority queues, you don’t care about keeping messages in the queue after they are processed, and you don’t expect an extreme throughput (although 100k messages/s that you can get in some RabbitMQ As A Service solutions, even in a high availability scenario, is in most cases more than enough).
Kafka
Kafka is a distributed streaming platform which takes a different approach than RabbitMQ - it implements a dumb broker/smart consumer model. In that case, it is the responsibility of the consumers to fetch messages and keep track of their state. What is unique about Kafka is the fact that it is not a message queue - it is an append-only log. Producers send messages to the topics, to which consumers subscribe and read the messages and keep the offset which is the information about the position in the log until which the messages were read. It can be illustrated the following way:
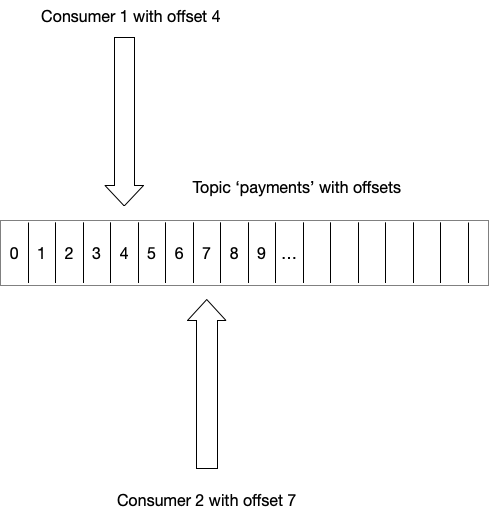
Such a design opens a way to some interesting features. The log is persistent with configurable retention which can be based on the size or time how long the events should be kept in the log, which makes Kafka act like a circular buffer. To save some space, Kafka allows log compaction when the messages are sent with the same key, keeping only the last one as a result. If storage is not an issue, you might even decide never to delete any messages!
On top of that, Kafka can easily handle a massive throughput - 100 000 messages/second is not extraordinary, it’s easy to scale, and there are cases of handling millions of messages per second.
A persistent log is a killer-feature of Kafka. When you add another service to your ecosystem and need to get the data from one app to another, you will run into obvious issues when using a traditional message queue since the messages are gone after they are processed. With Kafka, just can add a new consumer and replay all the past events! You can also combine Kafka with stream processing frameworks like Apache Samza, Apache Spark, Apache Storm,KSQL or use Kafka Streams.
Kafka is an excellent choice for use cases where the routing is not complex, the throughput is substantial, the messages need to stay in the log (even indefinitely) and where you expect the need to replay messages. You can also do Event Sourcing with Kafka and use stream processor like Kafka Stream or KSQL to construct projections from the events.
Summary
Communication between multiple services in a distributed ecosystem is far from a trivial problem, which can be approached in various ways: via a shared database (although to a very limited extent), HTTP APIs or messages.
In the next parts I’ll be focusing on Kafka and RabbitMQ - how they work and how to use them in Rails applications, how to produce and consume messages, what kind of extra options you get by introducing Kafka and RabbitMQ to your ecosystem, potential issues you might have in some specific scenarios and show some examples where combining both could bring benefits.