Messages on Rails Part 3: RabbitMQ
In the first part of this series, we were exploring some potential options for communication between services - what their advantages and disadvantages are, why HTTP API is not necessarily the best possible choice and suggesting that asynchronous messaging might be a better solution, using, e.g. RabbitMQ and Kafka. We’ve already covered Kafka in the part 2, now it’s the time for RabbitMQ.
What is RabbitMQ, and how does it work?
RabbitMQ is a general purpose message broker supporting multiple protocols, yet, we are going to focus mostly on AMQP, which is the one that is the most typically used. It implements a smart broker/dumb consumer model. Unlike Kafka, it means that the broker is responsible for delivering messages to the right place. Also, the queue in Rabbit is what you would naturally consider being a queue - it’s not database-like storage as Kafka topics are.
So what does publishing and consuming a message actually mean?
In the first step, a producer publishes a message - this can be a JSON message or whatever else that could be sent. This message is delivered to a queue, from which consumers can read it and process it. After the message is consumed, it’s gone from the queue.
If this sounds to you like Redis and Sidekiq, you would be quite right. Actually, Redis could also be used as a message queue for communication between apps, although that might not be necessarily the best idea as being a message queue is not its primary purpose.
Why is RabbitMQ is so unique though, and what can it do that Redis or even Kafka can’t do?
One of the key characteristics of RabbitMQ is that producers don’t push messages directly to the queues. Instead, producers send messages to another layer called exchanges. This has quite profound consequences on the way RabbitMQ can be used and the features it offers:
- Producers don’t need to be aware of all the queues where the message should be delivered, which means excellent decoupling between producers and consumers and ease of use
- Without exchanges, it would not be possible to easily implement a publish-subscribe pattern where multiple consumers need to process a given message. Instead, you would have pretty much something like in Sidekiq - when the message is pushed to the queue, the workers compete for it, and it gets processed only once, there is no case of multiple workers handling the same message. However, competing consumers pattern is still possible in RabbitMQ (we will see it later but rather as something to avoid in that particular case).
- Having extra layer in-between allows flexible routing and the implementation of some rules telling how and under what conditions consumers want to have messages delivered.
In general, we could visualize the flow in RabbitMQ in the following way:
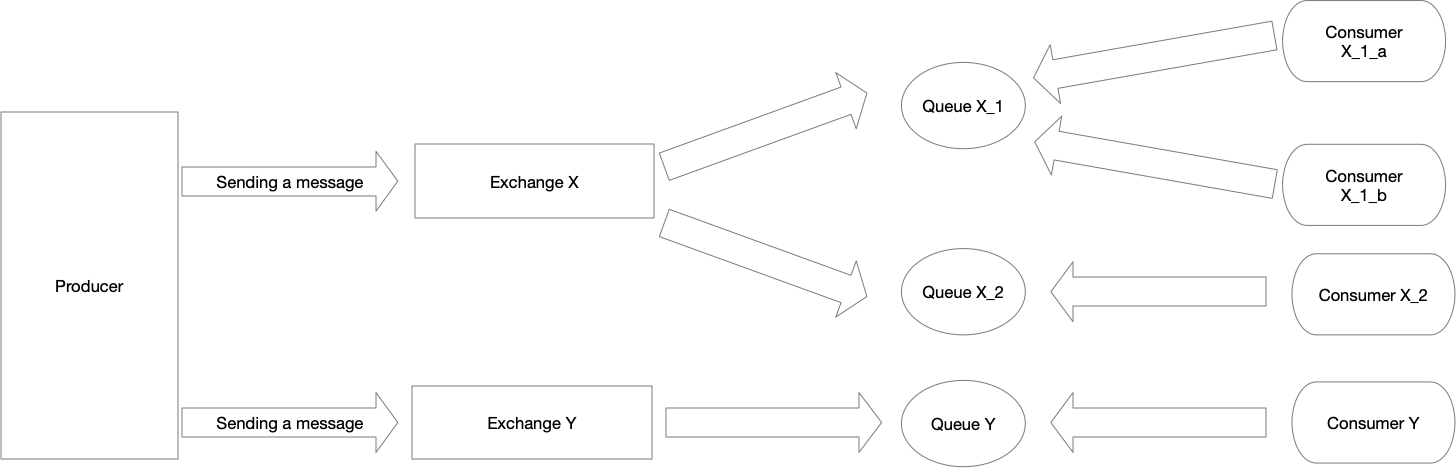
Publishing/Receiving messages and exchanges
Ability to implement a publish-subscribe pattern is a natural consequence of having exchanges. As we could see on the graph above, the producer is not aware of all of the queues to which the messages will be delivered. It might be even the case that there are no queues at all that would be interested in any message!
For the queues to receive messages, we need to create a relationship between that queue and the exchange. In RabbitMQ it’s called a binding.
So far, we know that the publisher sends a message to the exchange and exchange delivers the messages to queues that are bound to it. But what are the rules here that would determine to which queues exactly the message should be delivered to (besides the fact that the queues must have established a binding with the exchange)?
To achieve that, we have four types of exchange types that have a bit different behavior:
fanoutexchange - it just delivers a message to all the queues that are bound to it.direct- a given queue might be only interested in some particular type of messages that could be filtered out by some criteria. E.g., you might be publishing logs with different levels, just like inRails.loggerwhere you havedebug,info,fataletc. severity levels. In that case, there might be a queue that wants to receive onlyfatallogs, and another one might want to receive justdebuglogs. Instead of letting the consumer do the filtering itself, we can let RabbitMQ do it by specifying arouting keyin the message. We could publish logs with routing keys such aslog.debugandlog.fataland let the queues bind accordingly using that routing key as abinding key. That’s exactly what adirectexchange is about. However, what if we want to have a third queue that would be interested in all types of logs? In that case, we would need to use another kind of exchange:topic- it’s the exchange that allows receiving messages based on the patterns. In case of the example of logs, the queue that would be interested in all kinds of logs could create a binding withlog.*routing key. And what if it were interested in receiving all messages (i.e., work as afanoutexchange, even though we are usingtopicexchange here)? RabbitMQ has us covered, we could use a special routing key:#and that would be enough. Also, thetopicexchange can also act as adirectone - there is nothing preventing a queue from binding with a full routing key name, so using more “advanced” exchange type is only adding more options and flexibility, it doesn’t take away the features of “simpler” ones.headersexchange type - arguably a less common one, it’s quite similar totopicexchange, although the filtering is performed based on the values of the headers instead of routing keys.
Using RabbitMQ in Ruby/Rails apps
RPC with RabbitMQ
There is one somewhat unexpected feature of RabbitMQ (at least if you focus on async messaging) - Remote Procedure Call (RPC). That way you can implement synchronous request-reply flow, just like with HTTP APIs. So if it’s just like good ol’ HTTP API, why would you even consider RPCs via RabbitMQ?
Sometimes you might not need REST API as you might be interested only in executing a specific set of commands/procedures in another service that don’t easily map to resources that you would expose in REST API. It is especially true if you develop a private API which is not going to be exposed to Third Party Users, so there is little concern for “externalization”.
Let’s check a quick example to see it in action. To make RPC with RabbitMQ what we need to do is to publish a message and specify a reply-to (callback) queue to which the server will reply.
Let’s implement a classic: a Fibonacci sequence server to which the clients will be sending the numbers and expecting the result in the response. One of the super simple ways to implement RPCs in Ruby is to do it via bunny_borrow gem. To see it almost right away in action, you could add it to a Gemfile of any Rails application, open two Rails console processes, execute this code in the first one:
class Fibonacci
def self.calculate(number, accum = {})
return number if number == 0 || number == 1
accum[number] ||= calculate(number - 1, accum) + calculate(number-2, accum)
end
end
rpc_server = BunnyBurrow::Server.new do |server|
server.rabbitmq_url = "amqp://guest:guest@localhost:5672"
server.rabbitmq_exchange = "fibonacci_sequence"
server.logger = Logger.new(STDOUT)
end
rpc_server.subscribe("fibonacci.route") do |payload|
BunnyBurrow::Server.create_response.tap do |response|
response[:result] = Fibonacci.calculate(JSON.parse(payload).fetch("number"))
end
end
rpc_server.wait
and this in the second one:
rpc_client = BunnyBurrow::Client.new do |client|
client.rabbitmq_url = "amqp://guest:guest@localhost:5672"
client.rabbitmq_exchange = "fibonacci_sequence"
client.logger = Logger.new(STDOUT)
end
payload = { "number" => 10 }
response = rpc_client.publish(payload, "fibonacci.route")
puts JSON.parse(response)["result"]
Just don’t forget to install RabbitMQ before ;).
And that’s it! You will see the result of 55 getting printed. RPC with bunny_borrow merely requires binding to the right exchange, agreeing on the routing key we are going to use and publishing a message!
Background jobs with Sneakers - Redis/Sidekiq replacement
As already mentioned before, RabbitMQ can be a bit like Redis for background processing purposes. And it turns out that we even have a reliable replacement for Sidekiq that is backed by RabbitMQ! We can easily implement workers with sneakers gem, especially if you use ActiveJob as we have already adapter for Sneakers! But even if you use Sneakers standalone, you shouldn’t expect too many surprises there. It looks like a regular worker class. The only difference is that it requires manual acknowledgment of having the message processed:
class MySneakersWorker
include Sneakers::Worker
from_queue :queue_name
def work(payload)
Rails.logger.info "From Sneakers: #{payload}"
ack!
end
end
If you are curious why you might want to prefer Sneaker over Sidekiq, I would recommend reading the docs.
Event-Driven Applications with Hutch
The case where RabbitMQ really will shine in our Rails applications is for event-driven architecture or in general, publish-subscribe use cases. It happens quite often in communication between microservices that we don’t necessarily need synchronous calls between two or more apps and making it async will improve the efficiency, scalability and also will allow making the apps more independent, coherent and less coupled to each other. For example, if one application is down, we don’t need to worry about this as our message will be processed eventually when the app is back. For synchronous flow, that would be very different as we would need to implement error handling and simply be prepared for that kind of scenario. Also, quite often, there is a clear distinction between primary logic behind some use cases and secondary logic.
Consider the following scenario: you have a checkout page in your e-commerce system where a user can enter credit card data and pay for the order. Are all the following “features” equally important?
- executing the charge and confirming the order
- sending an email notification to the buyer
- sending WhatsApp message someone who will be responsible for delivering this order
- updating some internal stats about the orders
The first one is clearly the critical part of the logic, and the rest looks like some extra aspects that happen after the order is paid. Should they be called from the same place? And how does it go with the Single Responsibility Principle?
Let’s visualize this scenario with the following pseudocode:
class Order::ConfirmByPayment
def call(order, payment)
order.confirm!(payment)
send_notification_to_the buyer(order)
send_whatsapp_message_for_delivery(order)
update_stats_for_orders(order)
update_stats_for_payment(payment)
end
# private methods go here
end
Certainly, this class looks too busy as it is now. And what if we introduced some extra notifications or other aspects? Would we add just another private method? It doesn’t sound exactly like something compliant with SRP.
So what options do we have? One way to deal with it is to go with publish-subscribe pattern - publish some domain event and implement subscribers that would react to this event. It is doable in Rails apps without too much hassle with wisper gem. Explaining how to use wisper is outside the scope of this article, but to cut a long story short, that’s what this service would look like after a rewrite to event-driven architecture:
class Order::ConfirmByPayment
include Wisper::Publisher
def call(order, payment)
order.confirm!(payment)
broadcast(:order_confirmed_by_payment, order.as_json, payment.as_json)
end
# private methods go here
end
Each of the notification could be extracted to a separate class that is subscribed to order_confirmed_by_payment event. And that way, we would get clean and decoupled classes where the logic is easy to extend.
What does it have to do with RabbitMQ though?
In the code we’ve just gone through, everything is implemented within the same application. However, this is not really necessary. Sending notifications can be async, and it’s not needed to be done from the same application, we could have a separate service for stats, for sending email notifications, for sending WhatsApp messages etc. And for that, we need some simple way how to inform all the applications that they should do something. And that’s where we will need RabbitMQ and one of the Ruby “frameworks” that is built for this kind of use cases.
Building Example Producer and Consumer With RabbitMQ and Hutch
We are going to use hutch gem to publish event order.confirmed_by_payment event so that some consumers (either within the same app or from apps, it doesn’t make much difference) can do something upon it.
Hutch itself is quite opinionated, so there is not much left for us to figure out, yet, it’s good to keep in mind that it uses topic exchanges.
Let’s get back to our Order::ConfirmByPayment and publish a message with Hutch from there:
class Order::ConfirmByPayment
def call(order, payment)
order.confirm!(payment)
Hutch.connect
Hutch::Config.set(:force_publisher_confirms, true)
Hutch.publish("order.confirmed_by_payment", payment: payment.as_json, order: order.as_json)
end
end
The logic is quite simple: first, we need to connect Hutch. That’s probably not the place where it should be executed, some initializer might be a better idea, but it’s in this class to keep the example simpler. It’s the same thing with force_publisher_confirms option (that should be moved to some initializer as well) which we use here for extra durability and better guarantees as we require the publisher to wait for the confirmation that the message was published. And then, we publish our message with payment and order keys and their serialized projections as values under order.confirmed_by_payment routing key.
To consume the messages that are published by this class, we need some consumer classes:
class Order::ConfirmedByPaymentStatsUpdaterConsumer
include Hutch::Consumer
consume "order.confirmed_by_payment"
def process(message)
do_something_with_payment_and_order(message.body[:payment], message.body[:order])
end
end
class Order::ConfirmedByPaymentWhatsAppNotifierConsumer
include Hutch::Consumer
consume "order.confirmed_by_payment"
def process(message)
do_something_with_payment(message.body[:payment])
end
end
class Order::ConfirmedByPaymentEmailNotifierConsumer
include Hutch::Consumer
consume "order.confirmed_by_payment"
def process(message)
do_something_with_order(message.body[:order])
end
end
And that’s it! What we need to do is to define consumer classes that include Hutch::Consumer module, define the routing key under which we are going to consume messages and implement process method that will deal with the message that we get and do something with its body that contains what we published via publisher.
Optionally, we may want to specify queue_name explicitly, which is by default generated based on the class name. It will work without an explicit declaration for the majority of the cases, but what is going to happen if we have a consumer with the same class name in more than one application? Instead of having a publish-subscribe pattern, we are going to end up with competing consumers as having the same queue names is the way to do in RabbitMQ! In that case, it’s worth prefixing queue name with the app’s name or something else that would make it unique in your ecosystem:
class Order::ConfirmedByPaymentWhatsAppNotifierConsumer
include Hutch::Consumer
consume "order.confirmed_by_payment"
queue_name "notifs_app_order_confirmed_by_payments_whats_app_notifier"
def process(message)
do_something_with_payment(message.body[:payment])
end
end
The last thing to do is to start the worker process that will consume the messages:
bundle exec hutch
You should see an output that looks like this:
2019-06-15T19:27:52Z 84284 INFO -- hutch booted with pid 84284
2019-06-15T19:27:52Z 84284 INFO -- found rails project (.), booting app in development environment
2019-06-15T19:27:57Z 84284 INFO -- connecting to rabbitmq (amqp://guest@127.0.0.1:5672/)
2019-06-15T19:27:57Z 84284 INFO -- connected to RabbitMQ at 127.0.0.1 as guest
2019-06-15T19:27:57Z 84284 INFO -- opening rabbitmq channel with pool size 1, abort on exception false
2019-06-15T19:27:57Z 84284 INFO -- using topic exchange 'hutch'
2019-06-15T19:27:57Z 84284 INFO -- HTTP API use is enabled
2019-06-15T19:27:57Z 84284 INFO -- connecting to rabbitmq HTTP API (http://guest@127.0.0.1:15672/)
2019-06-15T19:27:57Z 84284 INFO -- tracing is disabled
2019-06-15T19:27:57Z 84284 INFO -- setting up queues
And you can enjoy using RabbitMQ in your apps and having the logic nicely decoupled with a little cost ;)
Wrapping Up
RabbitMQ is an excellent choice if you need multiple applications to talk to each other via events instead of HTTP requests/responses and should you ever need synchronous calls, you could take advantage of its RPC capabilities. It’s a mature message broker with well-established Ruby gems that will make it simple to introduce it in your Rails apps.